Reconstructing a coagulant optimization model using R and Shiny
Inspired by Lindsay Anderson’s suggestion that “somebody code up that Edwards 1997 model”, I successfully avoided proofreading my Ph.D. thesis proposal for much of a day doing just that. The paper is a classic paper, and one of many that attempt to predict dissolved organic carbon removal using easily measurable water quality parameters (in this case, absorbance of UV radiation at 254 nm, influent DOC concentration, and coagulant dose). Lindsay has a great paper talking about why coagulant dosing is important in an era of rapidly changing source water quality!
I was curious if there was enough information in the paper to replicate its results, having just attended Garret Grolemund's fantastic talk at RStudio::conf(2019) about the reproducibility crisis. To make a long story short, the coefficients in the paper seem to hold up, although there isn’t any data to validate the model fits. Feel free to skip straight to the shiny app to skip the math bits.
The paper presents a non-linear set of equations that describe how organic carbon interacts with a coagulant (in this case, an iron- or alum-based one). The equations are summarised in their final form part-way through the paper:
\[ \frac{\text{DOC}_\text{initial}(1 - \text{SUVA} \cdot K_1 - K_2) - \text{[C]}_\text{eq}}{M} = \frac{a b \text{[C]}_\text{eq}}{1 + b \text{[C]}_\text{eq}} \]
Here, \(a\) is related to pH via a 3rd-degree polynomial (\(a = x_3\text{pH}^3 + x_2\text{pH}^2 + x_1\text{pH}\)). The even though the paper is trying to predict the final DOC conentration (Ceq), the equation never appears in the article in its solved form! This is because the solving happened using Excel Solver, and so it never needed to be. To do this in R, however, we’ll need a solved form.
The details: Let \(S = 1 - \text{SUVA} \cdot K_1 - K_2\), \(D = \text{DOC}_\text{initial}\), \(C = \text{[C]}_\text{eq}\)
\[ \frac{DS - C}{M} = \frac{abC}{1 + bC} \]
Cross-multiply:
\[ (DS - C) (1 + bC) = MabC \]
Expand left side, subtract \(MabC\)
\[ DS + DSbC - C - bC^2 - MabC = 0 \]
Simplify to a quadratic:
\[ -bC^2 + (DSb - 1 - Mab)C + DS = 0 \]
Use the quadratic formula \(x = \frac{-b \pm \sqrt{b^2 - 4ac}}{2a}\):
\[ C = \frac{ -(DSb - 1 - Mab) \pm \sqrt{(DSb - 1 - Mab)^2 -4(-b)(DS)} }{2(-b)} \]
Note that this solution requires that \(b \ne 0\) and \(M \ne 0\). The b paramter is one we set, so that can be arranged, but the fact that a zero dose is not allowed suggests that the model isn’t valid when no dose (or low dose, probably) is applied. If you play with the model parameters on the shiny app, you’ll notice it’s possible to get a higher final dose than initial dose…this is probably why.
Instead of plugging back in the substitutions (which seems unlikely to go right without a lot of checking), I’ll code them in such that we have an R function that can predict the final DOC concentration given the model inputs. I’ve included the coefficients for Edwards’ general model for alum as the default parameter arguments.
param_S <- function(SUVA, K1, K2) 1 - SUVA * K1 - K2
param_a <- function(pH, x1, x2, x3) pH^3 * x3 + pH^2 * x2 + pH * x1
param_SUVA <- function(UV254_per_cm, DOC_mg_L) 100 * UV254_per_cm / DOC_mg_L
param_UV254_per_cm = function(SUVA, DOC_mg_L) SUVA * DOC_mg_L / 100
doc_final <- function(dose_mmol_L, DOC_initial_mg_L, pH, UV254_per_cm,
K1 = -0.054, K2 = 0.54, x1 = 383, x2 = -98.6, x3 = 6.42, b = 0.107,
root = c("plus", "minus")) {
root <- match.arg(root)
coeff <- unname(c(plus = 1, minus = -1)[root])
D <- DOC_initial_mg_L
M <- dose_mmol_L
SUVA <- param_SUVA(UV254_per_cm, DOC_initial_mg_L)
S <- param_S(SUVA, K1, K2)
a <- param_a(pH, x1, x2, x3)
first_term <- -(D * S * b - 1 - M * a * b)
sqrt_term <- sqrt((D * S * b - 1 - M * a * b)^2 - 4 * (-b * D * S))
denominator <- 2 * (-b)
Ceq <- (first_term + coeff * sqrt_term) / denominator
Ceq
}
In the paper, it is hinted that a number of source waters were tested, although the data is not available to validate the model fits. Still, the basic parameters are provided, so we can see if the model produces reasonable results.
waters <- tribble(
~water_number, ~SUVA, ~DOC_initial_mg_L,
1, 1.42, 2.6,
2, 2.2, 2.63,
3, 3.08, 2.3,
4, 2.66, 2.7,
5, 3.52, 2.56,
6, 3.1, 3.1,
7, 2.71, 3.94,
8, 2.77, 4.8,
9, 3.27, 4.4,
10, 3.43, 6.5,
11, 2.43, 12.7,
12, 3.65, 11.3,
13, 4.09, 11.6,
14, 4.67, 14.3,
15, 6.11, 8.03,
16, 5.11, 26.54
) %>%
mutate(
label = paste(DOC_initial_mg_L, "mg/L, SUVA:", SUVA),
UV254_per_cm = param_UV254_per_cm(SUVA, DOC_initial_mg_L)
)
waters
## # A tibble: 16 x 5
## water_number SUVA DOC_initial_mg_L label UV254_per_cm
## <dbl> <dbl> <dbl> <chr> <dbl>
## 1 1 1.42 2.6 2.6 mg/L, SUVA: 1.42 0.0369
## 2 2 2.2 2.63 2.63 mg/L, SUVA: 2.2 0.0579
## 3 3 3.08 2.3 2.3 mg/L, SUVA: 3.08 0.0708
## 4 4 2.66 2.7 2.7 mg/L, SUVA: 2.66 0.0718
## 5 5 3.52 2.56 2.56 mg/L, SUVA: 3.52 0.0901
## 6 6 3.1 3.1 3.1 mg/L, SUVA: 3.1 0.0961
## 7 7 2.71 3.94 3.94 mg/L, SUVA: 2.71 0.107
## 8 8 2.77 4.8 4.8 mg/L, SUVA: 2.77 0.133
## 9 9 3.27 4.4 4.4 mg/L, SUVA: 3.27 0.144
## 10 10 3.43 6.5 6.5 mg/L, SUVA: 3.43 0.223
## 11 11 2.43 12.7 12.7 mg/L, SUVA: 2.43 0.309
## 12 12 3.65 11.3 11.3 mg/L, SUVA: 3.65 0.412
## 13 13 4.09 11.6 11.6 mg/L, SUVA: 4.09 0.474
## 14 14 4.67 14.3 14.3 mg/L, SUVA: 4.67 0.668
## 15 15 6.11 8.03 8.03 mg/L, SUVA: 6.11 0.491
## 16 16 5.11 26.5 26.54 mg/L, SUVA: 5.11 1.36
In addition to a number of source waters, I’ll also try a number of parameter combinations.
params <- list(
pH = seq(3, 8, by = 1),
AlSO4_mg_L = seq(5, 60, by = 1)
) %>%
cross_df()
params
## # A tibble: 336 x 2
## pH AlSO4_mg_L
## <dbl> <dbl>
## 1 3 5
## 2 4 5
## 3 5 5
## 4 6 5
## 5 7 5
## 6 8 5
## 7 3 6
## 8 4 6
## 9 5 6
## 10 6 6
## # … with 326 more rows
Finally, we can “run” the model. In this case, I coded the model such that it was vectorized, so given a data frame with all the conbinations, the model results can all be generated in one function call.
model_output <- crossing(waters, params) %>%
mutate(
AlSO4_mmol_L = AlSO4_mg_L / 123.04,
DOC_final_mg_L = doc_final(
dose_mmol_L = AlSO4_mmol_L,
DOC_initial_mg_L = DOC_initial_mg_L,
pH = pH,
UV254_per_cm = UV254_per_cm,
root = "minus"
)
)
model_output
## # A tibble: 5,376 x 9
## water_number SUVA DOC_initial_mg_L label UV254_per_cm pH AlSO4_mg_L
## <dbl> <dbl> <dbl> <chr> <dbl> <dbl> <dbl>
## 1 1 1.42 2.6 2.6 … 0.0369 3 5
## 2 1 1.42 2.6 2.6 … 0.0369 4 5
## 3 1 1.42 2.6 2.6 … 0.0369 5 5
## 4 1 1.42 2.6 2.6 … 0.0369 6 5
## 5 1 1.42 2.6 2.6 … 0.0369 7 5
## 6 1 1.42 2.6 2.6 … 0.0369 8 5
## 7 1 1.42 2.6 2.6 … 0.0369 3 6
## 8 1 1.42 2.6 2.6 … 0.0369 4 6
## 9 1 1.42 2.6 2.6 … 0.0369 5 6
## 10 1 1.42 2.6 2.6 … 0.0369 6 6
## # … with 5,366 more rows, and 2 more variables: AlSO4_mmol_L <dbl>,
## # DOC_final_mg_L <dbl>
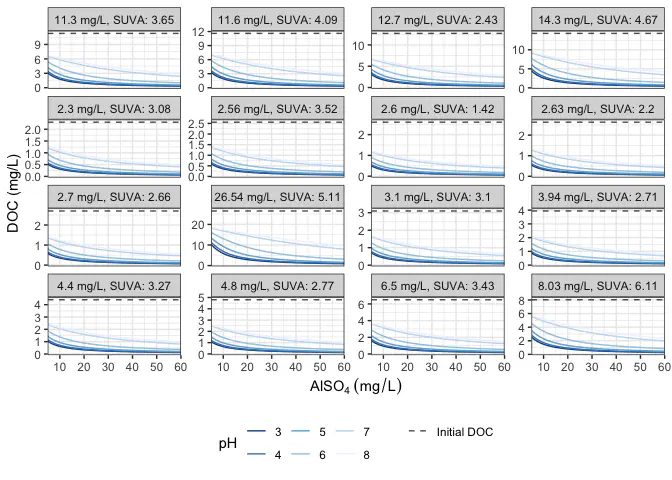
Finally, we can visualize!
ggplot(model_output, aes(x = AlSO4_mg_L, y = DOC_final_mg_L, col = factor(pH))) +
geom_hline(aes(yintercept = DOC_initial_mg_L, lty = "Initial DOC"), data = waters, alpha = 0.7) +
scale_linetype_manual(values = 2) +
geom_line() +
scale_color_brewer(direction = -1) +
theme_bw() +
facet_wrap(vars(label), scales = "free_y") +
scale_x_continuous(expand = expand_scale(0, 0)) +
theme(legend.position = "bottom") +
labs(x = expression(AlSO[4]~(mg/L)), y = "DOC (mg/L)", col = "pH", linetype = NULL)
If you have’t already, check out the shiny app and play with a few of the parameters in the model! In short, it would have been nice to have the data to validate the model, although to Edwards’ credit, it was 1997.